 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Sketch Synthesis
Face sketch synthesis is the process of generating realistic face sketches from photographs or descriptions.
Papers and Code
MMFace-DiT: A Dual-Stream Diffusion Transformer for High-Fidelity Multimodal Face Generation
Mar 30, 2026Recent multimodal face generation models address the spatial control limitations of text-to-image diffusion models by augmenting text-based conditioning with spatial priors such as segmentation masks, sketches, or edge maps. This multimodal fusion enables controllable synthesis aligned with both high-level semantic intent and low-level structural layout. However, most existing approaches typically extend pre-trained text-to-image pipelines by appending auxiliary control modules or stitching together separate uni-modal networks. These ad hoc designs inherit architectural constraints, duplicate parameters, and often fail under conflicting modalities or mismatched latent spaces, limiting their ability to perform synergistic fusion across semantic and spatial domains. We introduce MMFace-DiT, a unified dual-stream diffusion transformer engineered for synergistic multimodal face synthesis. Its core novelty lies in a dual-stream transformer block that processes spatial (mask/sketch) and semantic (text) tokens in parallel, deeply fusing them through a shared Rotary Position-Embedded (RoPE) Attention mechanism. This design prevents modal dominance and ensures strong adherence to both text and structural priors to achieve unprecedented spatial-semantic consistency for controllable face generation. Furthermore, a novel Modality Embedder enables a single cohesive model to dynamically adapt to varying spatial conditions without retraining. MMFace-DiT achieves a 40% improvement in visual fidelity and prompt alignment over six state-of-the-art multimodal face generation models, establishing a flexible new paradigm for end-to-end controllable generative modeling. The code and dataset are available on our project page: https://vcbsl.github.io/MMFace-DiT/
One-shot Face Sketch Synthesis in the Wild via Generative Diffusion Prior and Instruction Tuning
Jun 18, 2025


Face sketch synthesis is a technique aimed at converting face photos into sketches. Existing face sketch synthesis research mainly relies on training with numerous photo-sketch sample pairs from existing datasets. However, these large-scale discriminative learning methods will have to face problems such as data scarcity and high human labor costs. Once the training data becomes scarce, their generative performance significantly degrades. In this paper, we propose a one-shot face sketch synthesis method based on diffusion models. We optimize text instructions on a diffusion model using face photo-sketch image pairs. Then, the instructions derived through gradient-based optimization are used for inference. To simulate real-world scenarios more accurately and evaluate method effectiveness more comprehensively, we introduce a new benchmark named One-shot Face Sketch Dataset (OS-Sketch). The benchmark consists of 400 pairs of face photo-sketch images, including sketches with different styles and photos with different backgrounds, ages, sexes, expressions, illumination, etc. For a solid out-of-distribution evaluation, we select only one pair of images for training at each time, with the rest used for inference. Extensive experiments demonstrate that the proposed method can convert various photos into realistic and highly consistent sketches in a one-shot context. Compared to other methods, our approach offers greater convenience and broader applicability. The dataset will be available at: https://github.com/HanWu3125/OS-Sketch
Multi-Style Facial Sketch Synthesis through Masked Generative Modeling
Aug 22, 2024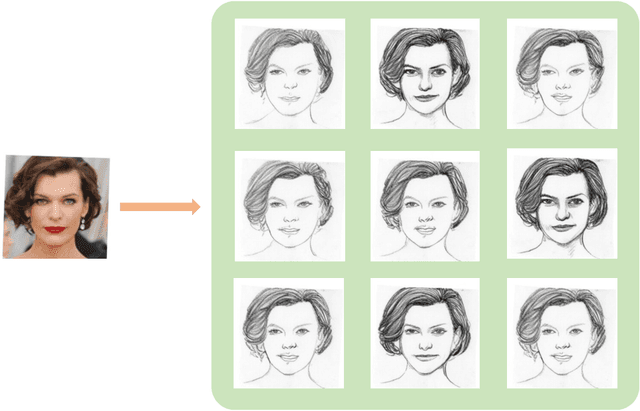
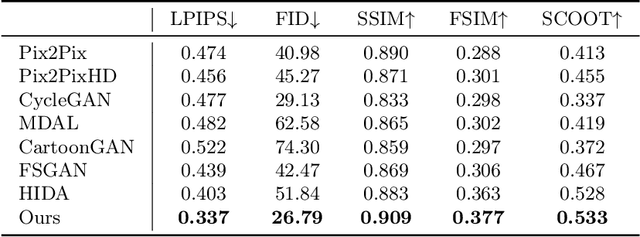
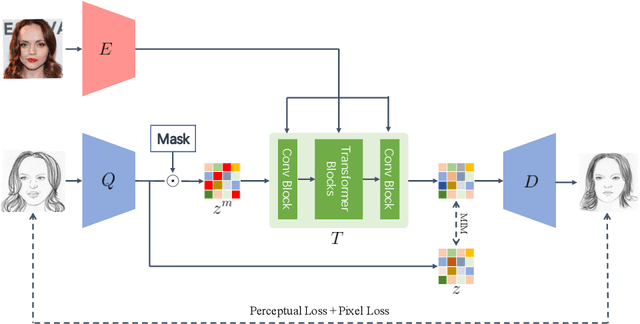

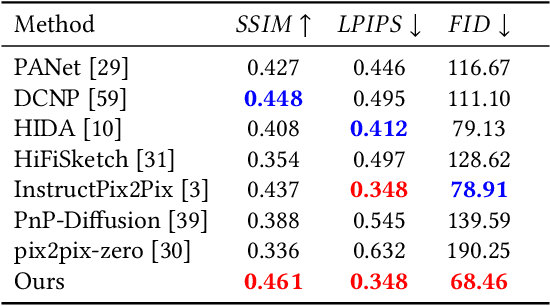
The facial sketch synthesis (FSS) model, capable of generating sketch portraits from given facial photographs, holds profound implications across multiple domains, encompassing cross-modal face recognition, entertainment, art, media, among others. However, the production of high-quality sketches remains a formidable task, primarily due to the challenges and flaws associated with three key factors: (1) the scarcity of artist-drawn data, (2) the constraints imposed by limited style types, and (3) the deficiencies of processing input information in existing models. To address these difficulties, we propose a lightweight end-to-end synthesis model that efficiently converts images to corresponding multi-stylized sketches, obviating the necessity for any supplementary inputs (\eg, 3D geometry). In this study, we overcome the issue of data insufficiency by incorporating semi-supervised learning into the training process. Additionally, we employ a feature extraction module and style embeddings to proficiently steer the generative transformer during the iterative prediction of masked image tokens, thus achieving a continuous stylized output that retains facial features accurately in sketches. The extensive experiments demonstrate that our method consistently outperforms previous algorithms across multiple benchmarks, exhibiting a discernible disparity.
PS-StyleGAN: Illustrative Portrait Sketching using Attention-Based Style Adaptation
Aug 31, 2024Portrait sketching involves capturing identity specific attributes of a real face with abstract lines and shades. Unlike photo-realistic images, a good portrait sketch generation method needs selective attention to detail, making the problem challenging. This paper introduces \textbf{Portrait Sketching StyleGAN (PS-StyleGAN)}, a style transfer approach tailored for portrait sketch synthesis. We leverage the semantic $W+$ latent space of StyleGAN to generate portrait sketches, allowing us to make meaningful edits, like pose and expression alterations, without compromising identity. To achieve this, we propose the use of Attentive Affine transform blocks in our architecture, and a training strategy that allows us to change StyleGAN's output without finetuning it. These blocks learn to modify style latent code by paying attention to both content and style latent features, allowing us to adapt the outputs of StyleGAN in an inversion-consistent manner. Our approach uses only a few paired examples ($\sim 100$) to model a style and has a short training time. We demonstrate PS-StyleGAN's superiority over the current state-of-the-art methods on various datasets, qualitatively and quantitatively.
SketchRef: A Benchmark Dataset and Evaluation Metrics for Automated Sketch Synthesis
Aug 16, 2024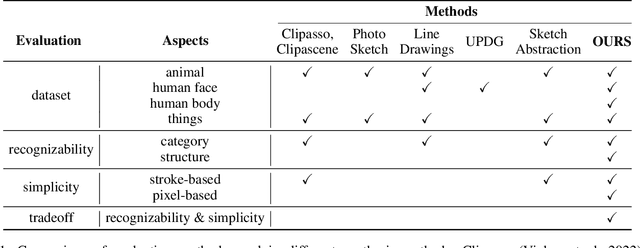
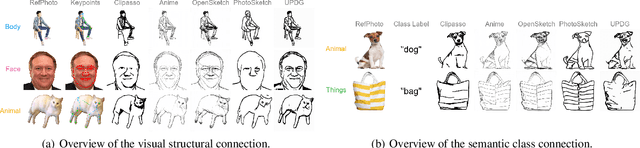

Sketch, a powerful artistic technique to capture essential visual information about real-world objects, is increasingly gaining attention in the image synthesis field. However, evaluating the quality of synthesized sketches presents unique unsolved challenges. Current evaluation methods for sketch synthesis are inadequate due to the lack of a unified benchmark dataset, over-reliance on classification accuracy for recognizability, and unfair evaluation of sketches with different levels of simplification. To address these issues, we introduce SketchRef, a benchmark dataset comprising 4 categories of reference photos--animals, human faces, human bodies, and common objects--alongside novel evaluation metrics. Considering that classification accuracy is insufficient to measure the structural consistency between a sketch and its reference photo, we propose the mean Object Keypoint Similarity (mOKS) metric, utilizing pose estimation to assess structure-level recognizability. To ensure fair evaluation sketches with different simplification levels, we propose a recognizability calculation method constrained by simplicity. We also collect 8K responses from art enthusiasts, validating the effectiveness of our proposed evaluation methods. We hope this work can provide a comprehensive evaluation of sketch synthesis algorithms, thereby aligning their performance more closely with human understanding.
semantic neural model approach for face recognition from sketch
May 01, 2023Face sketch synthesis and reputation have wide range of packages in law enforcement. Despite the amazing progresses had been made in faces cartoon and reputation, maximum current researches regard them as separate responsibilities. On this paper, we propose a semantic neural version approach so that you can address face caricature synthesis and recognition concurrently. We anticipate that faces to be studied are in a frontal pose, with regular lighting and neutral expression, and have no occlusions. To synthesize caricature/image photos, the face vicinity is divided into overlapping patches for gaining knowledge of. The size of the patches decides the scale of local face systems to be found out.
Semantic Image Synthesis with Unconditional Generator
Feb 22, 2024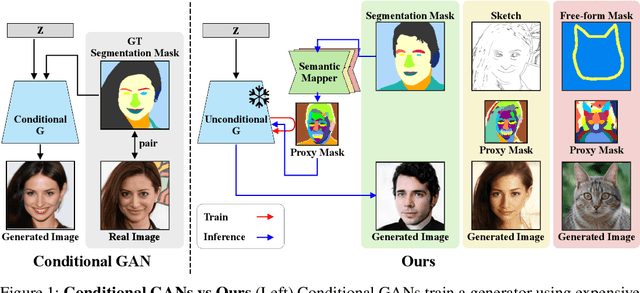
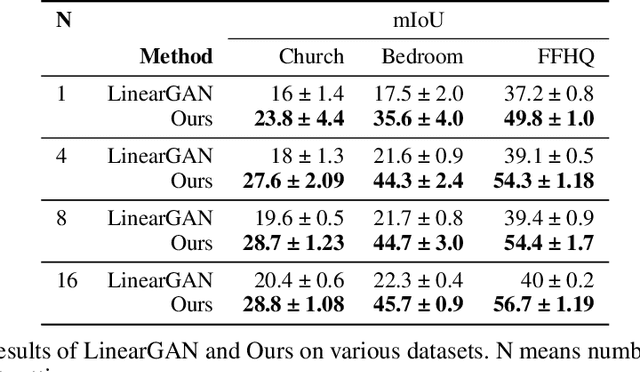
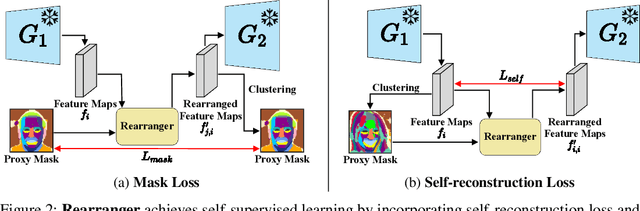
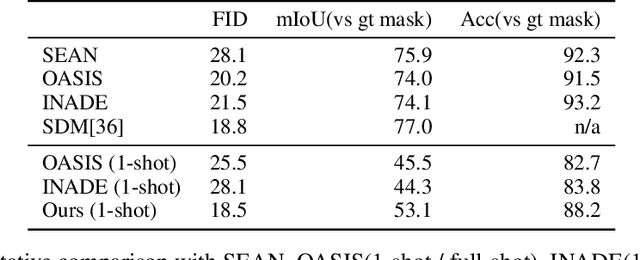
Semantic image synthesis (SIS) aims to generate realistic images that match given semantic masks. Despite recent advances allowing high-quality results and precise spatial control, they require a massive semantic segmentation dataset for training the models. Instead, we propose to employ a pre-trained unconditional generator and rearrange its feature maps according to proxy masks. The proxy masks are prepared from the feature maps of random samples in the generator by simple clustering. The feature rearranger learns to rearrange original feature maps to match the shape of the proxy masks that are either from the original sample itself or from random samples. Then we introduce a semantic mapper that produces the proxy masks from various input conditions including semantic masks. Our method is versatile across various applications such as free-form spatial editing of real images, sketch-to-photo, and even scribble-to-photo. Experiments validate advantages of our method on a range of datasets: human faces, animal faces, and buildings.
DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model
Feb 26, 2023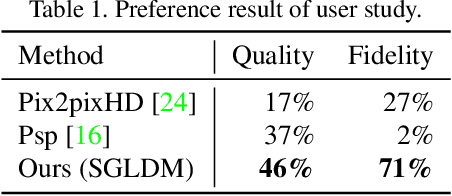

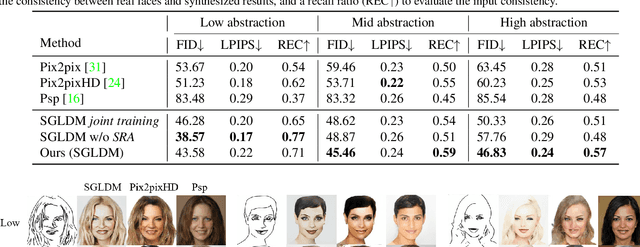
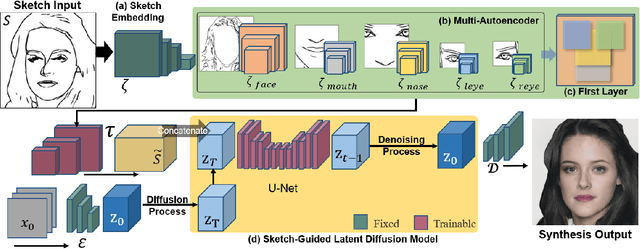
Synthesizing face images from monochrome sketches is one of the most fundamental tasks in the field of image-to-image translation. However, it is still challenging to (1)~make models learn the high-dimensional face features such as geometry and color, and (2)~take into account the characteristics of input sketches. Existing methods often use sketches as indirect inputs (or as auxiliary inputs) to guide the models, resulting in the loss of sketch features or the alteration of geometry information. In this paper, we introduce a Sketch-Guided Latent Diffusion Model (SGLDM), an LDM-based network architect trained on the paired sketch-face dataset. We apply a Multi-Auto-Encoder (AE) to encode the different input sketches from different regions of a face from pixel space to a feature map in latent space, which enables us to reduce the dimension of the sketch input while preserving the geometry-related information of local face details. We build a sketch-face paired dataset based on the existing method that extracts the edge map from an image. We then introduce a Stochastic Region Abstraction (SRA), an approach to augment our dataset to improve the robustness of SGLDM to handle sketch input with arbitrary abstraction. The evaluation study shows that SGLDM can synthesize high-quality face images with different expressions, facial accessories, and hairstyles from various sketches with different abstraction levels.
MOST-Net: A Memory Oriented Style Transfer Network for Face Sketch Synthesis
Feb 08, 2022
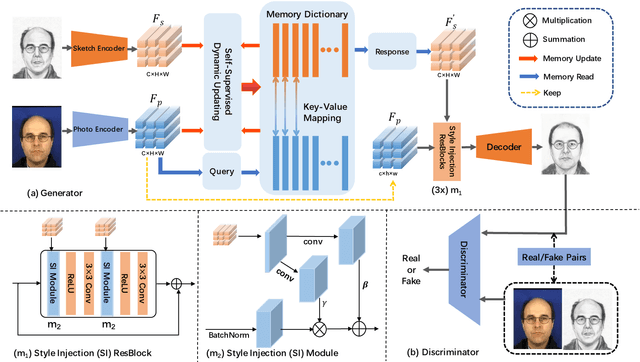
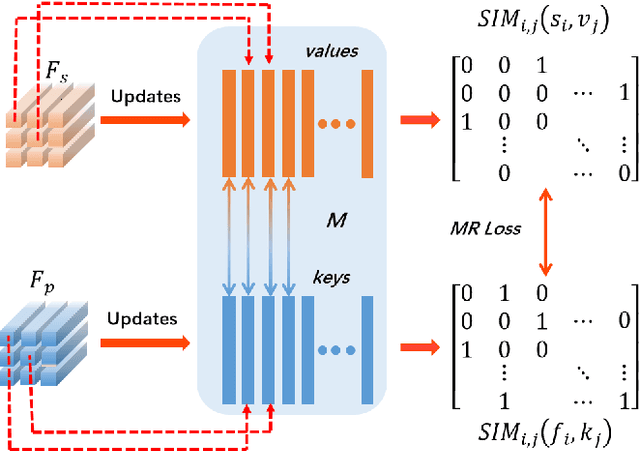
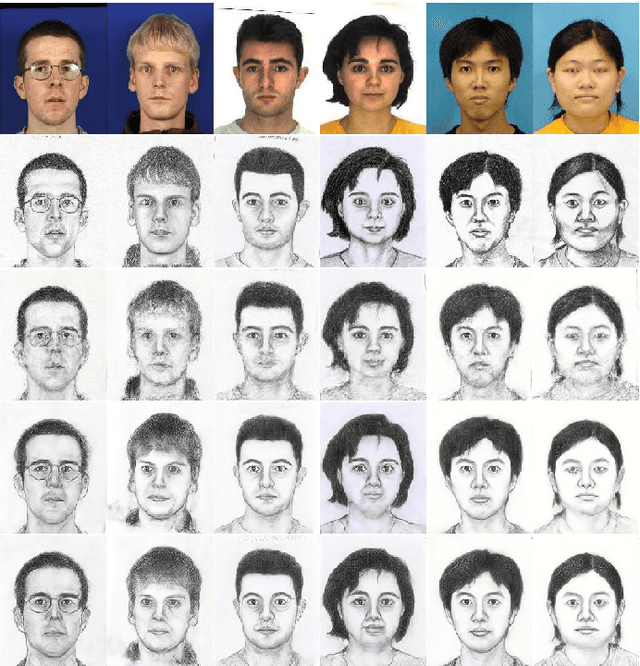
Face sketch synthesis has been widely used in multi-media entertainment and law enforcement. Despite the recent developments in deep neural networks, accurate and realistic face sketch synthesis is still a challenging task due to the diversity and complexity of human faces. Current image-to-image translation-based face sketch synthesis frequently encounters over-fitting problems when it comes to small-scale datasets. To tackle this problem, we present an end-to-end Memory Oriented Style Transfer Network (MOST-Net) for face sketch synthesis which can produce high-fidelity sketches with limited data. Specifically, an external self-supervised dynamic memory module is introduced to capture the domain alignment knowledge in the long term. In this way, our proposed model could obtain the domain-transfer ability by establishing the durable relationship between faces and corresponding sketches on the feature level. Furthermore, we design a novel Memory Refinement Loss (MR Loss) for feature alignment in the memory module, which enhances the accuracy of memory slots in an unsupervised manner. Extensive experiments on the CUFS and the CUFSF datasets show that our MOST-Net achieves state-of-the-art performance, especially in terms of the Structural Similarity Index(SSIM).
Human-Inspired Facial Sketch Synthesis with Dynamic Adaptation
Sep 01, 2023Facial sketch synthesis (FSS) aims to generate a vivid sketch portrait from a given facial photo. Existing FSS methods merely rely on 2D representations of facial semantic or appearance. However, professional human artists usually use outlines or shadings to covey 3D geometry. Thus facial 3D geometry (e.g. depth map) is extremely important for FSS. Besides, different artists may use diverse drawing techniques and create multiple styles of sketches; but the style is globally consistent in a sketch. Inspired by such observations, in this paper, we propose a novel Human-Inspired Dynamic Adaptation (HIDA) method. Specially, we propose to dynamically modulate neuron activations based on a joint consideration of both facial 3D geometry and 2D appearance, as well as globally consistent style control. Besides, we use deformable convolutions at coarse-scales to align deep features, for generating abstract and distinct outlines. Experiments show that HIDA can generate high-quality sketches in multiple styles, and significantly outperforms previous methods, over a large range of challenging faces. Besides, HIDA allows precise style control of the synthesized sketch, and generalizes well to natural scenes and other artistic styles. Our code and results have been released online at: https://github.com/AiArt-HDU/HIDA.